【构建pdf查询系统,可联系群主】
我们为这个教程创建了一个模块。您可以按照这些指示使用Clarifai模板创建自己的模块,或者直接在Clarifai Portal上使用这个模块本身。
大型语言模型(LLM)如GPT-3和GPT-4的出现彻底改变了人工智能领域。这些模型擅长生成类似人类的文本,回答问题,甚至创作具有说服力和连贯性的内容。然而,LLM也存在一些缺点;它们经常依赖于其训练数据中嵌入的过时或不正确的信息,并且可能产生不一致的回答。在潜力和可靠性之间存在的差距就是RAG发挥作用的地方。
RAG是一个创新的AI框架,旨在通过将其与准确和最新的外部知识库联系起来,增强LLMs的能力。RAG通过检索相关事实和数据来丰富LLMs的生成过程,以提供既令人信服又基于最新信息的回答。RAG既可以提高回答的质量,又可以提供生成过程的透明度,从而在基于AI的应用中培养信任和可信度。
RAG在一个多步骤的过程中运作,对传统的LLM输出进行了改进。它从数据组织开始,将大量的文本转化为更小、更易消化的块。这些块被表示为向量,它们作为特定信息的唯一数字地址。在收到查询后,RAG探索其庞大的向量数据库,以识别最相关的信息块,然后将其作为上下文提供给LLM。这个过程类似于在提问之前提供参考资料,但是在幕后进行处理。
RAG为LLM提供了一个丰富的提示,该提示现在配备了当前和相关的事实,以生成回答。这个回复不仅仅是模型内部的统计词语关联的结果,而是一段更加扎实和知情的文本,与输入的查询相一致。检索和生成过程是隐形的,为最终用户提供了一个准确、可验证和完整的答案。
这个简短的教程旨在通过使用streamlit、langchain和Clarifai库的实现示例,展示开发人员如何构建利用LLMs的优势并通过RAG减轻其限制的系统。
再次,您可以按照这些指示使用Clarifai模板创建自己的模块,或者只需在Clarifai门户上使用此模块本身,即可在不到5分钟内开始使用!
数据组织
在使用RAG之前,您需要将数据组织成可管理的部分,以便AI稍后可以参考。以下代码段用于将PDF文档分解为较小的文本块,然后由嵌入模型使用这些文本块创建向量表示。
代码解释:
该函数将上传的PDF文件读入内存。然后使用一个 CharacterTextSplitter 将这些文档的文本分割成1000个字符的块,没有任何重叠。
| # 1. Data Organization: chunk documents | |
| @st.cache_resource(ttl="1h") | |
| def load_chunk_pdf(uploaded_files): | |
| # Read documents | |
| documents = [] | |
| temp_dir = tempfile.TemporaryDirectory() | |
| for file in uploaded_files: | |
| temp_filepath = os.path.join(temp_dir.name, file.name) | |
| with open(temp_filepath, "wb") as f: | |
| f.write(file.getvalue()) | |
| loader = PyPDFLoader(temp_filepath) | |
| documents.extend(loader.load()) | |
| text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0) | |
| chunked_documents = text_splitter.split_documents(documents) | |
| return chunked_documents |
view raw1-data.py hosted with ❤ by GitHub
矢量创建
一旦您将文档分块,您需要将这些块转换为向量——这是AI能够高效理解和操作的形式。
代码解释:
该函数 vectorstore 负责使用Clarifai创建一个向量数据库。它接收用户凭证和分块的文档,然后使用Clarifai的服务存储文档向量。
| # Create vector store on Clarifai for use in step 2 | |
| def vectorstore(USER_ID, APP_ID, docs, CLARIFAI_PAT): | |
| clarifai_vector_db = Clarifai.from_documents( | |
| user_id=USER_ID, | |
| app_id=APP_ID, | |
| documents=docs, | |
| pat=CLARIFAI_PAT, | |
| number_of_docs=3, | |
| ) | |
| return clarifai_vector_db |
view raw2-vector.py hosted with ❤ by GitHub
设置问答模型
将数据整理成向量后,您需要设置使用准备好的文档向量的Q&A模型,该模型将使用RAG。
代码解释:
QandA 函数使用Langchain和Clarifai设置一个 RetrievalQA 对象。这是在这里,Clarifai的LLM模型被实例化,并且RAG系统使用"stuff"链类型进行初始化。
| def QandA(CLARIFAI_PAT, clarifai_vector_db): | |
| from langchain.llms import Clarifai | |
| USER_ID = "openai" | |
| APP_ID = "chat-completion" | |
| MODEL_ID = "GPT-4" | |
| clarifai_llm = Clarifai( | |
| pat=CLARIFAI_PAT, user_id=USER_ID, app_id=APP_ID, model_id=MODEL_ID) | |
| qa = RetrievalQA.from_chain_type( | |
| llm=clarifai_llm, | |
| chain_type="stuff", | |
| retriever=clarifai_vector_db.as_retriever() | |
| ) | |
| return qa |
view raw3-qa.py hosted with ❤ by GitHub
用户界面和交互
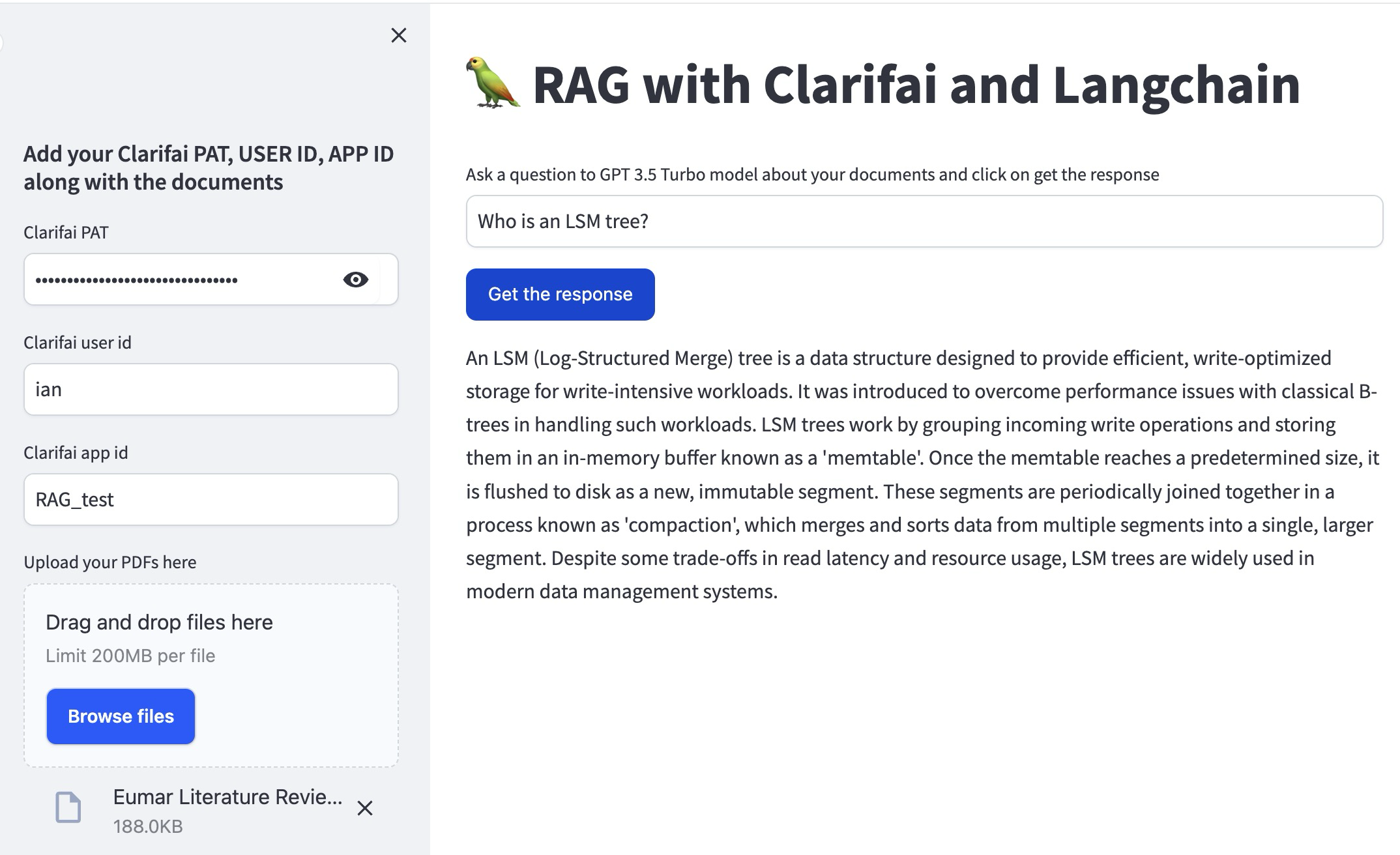
在这里,我们创建了一个用户界面,用户可以在其中输入他们的问题。收集输入和凭据,并在用户请求时生成响应。
代码解释:
这是使用Streamlit创建用户界面的 main 函数。用户可以输入他们的Clarifai凭证,上传文档并提问。该函数负责读取文档,创建向量存储,并运行问答模型以生成用户问题的答案。
| def main(): | |
| user_question = st.text_input("Ask a question to GPT 3.5 Turbo model about your documents and click on get the response") | |
| with st.sidebar: | |
| st.subheader("Add your Clarifai PAT, USER ID, APP ID along with the documents") | |
| CLARIFAI_PAT = st.text_input("Clarifai PAT", type="password") | |
| USER_ID = st.text_input("Clarifai user id") | |
| APP_ID = st.text_input("Clarifai app id") | |
| uploaded_files = st.file_uploader( | |
| "Upload your PDFs here", accept_multiple_files=True) | |
| if not (CLARIFAI_PAT and USER_ID and APP_ID and uploaded_files): | |
| st.info("Please add your Clarifai PAT, USER_ID, APP_ID and upload files to continue.") | |
| elif st.button("Get the response"): | |
| with st.spinner("Processing"): | |
| docs = load_chunk_pdf(uploaded_files) | |
| clarifai_vector_db = vectorstore(USER_ID, APP_ID, docs, CLARIFAI_PAT) | |
| conversation = QandA(CLARIFAI_PAT, clarifai_vector_db) | |
| response = conversation.run(user_question) | |
| st.write(response) | |
| if __name__ == '__main__': | |
| main() |
view raw4-main.py hosted with ❤ by GitHub
这里的最后一段代码是应用程序的入口点,如果直接运行脚本,Streamlit用户界面将被执行。它从用户输入到显示生成的答案,协调整个RAG过程。
将所有东西放在一起
这是该模块的完整代码。您可以在这里查看它的GitHub存储库,并在Clarifai平台上将其作为模块使用。
| import streamlit as st | |
| import tempfile | |
| import os | |
| from langchain.document_loaders import PyPDFLoader | |
| from langchain.text_splitter import CharacterTextSplitter | |
| from langchain.vectorstores import Clarifai | |
| from langchain.chains import RetrievalQA | |
| from clarifai.modules.css import ClarifaiStreamlitCSS | |
| st.set_page_config(page_title="Chat with Documents", page_icon="🦜") | |
| st.title("🦜 RAG with Clarifai and Langchain") | |
| ClarifaiStreamlitCSS.insert_default_css(st) | |
| # 1. Data Organization: chunk documents | |
| @st.cache_resource(ttl="1h") | |
| def load_chunk_pdf(uploaded_files): | |
| # Read documents | |
| documents = [] | |
| temp_dir = tempfile.TemporaryDirectory() | |
| for file in uploaded_files: | |
| temp_filepath = os.path.join(temp_dir.name, file.name) | |
| with open(temp_filepath, "wb") as f: | |
| f.write(file.getvalue()) | |
| loader = PyPDFLoader(temp_filepath) | |
| documents.extend(loader.load()) | |
| text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0) | |
| chunked_documents = text_splitter.split_documents(documents) | |
| return chunked_documents | |
| # Create vector store on Clarifai for use in step 2 | |
| def vectorstore(USER_ID, APP_ID, docs, CLARIFAI_PAT): | |
| clarifai_vector_db = Clarifai.from_documents( | |
| user_id=USER_ID, | |
| app_id=APP_ID, | |
| documents=docs, | |
| pat=CLARIFAI_PAT, | |
| number_of_docs=3, | |
| ) | |
| return clarifai_vector_db | |
| def QandA(CLARIFAI_PAT, clarifai_vector_db): | |
| from langchain.llms import Clarifai | |
| USER_ID = "openai" | |
| APP_ID = "chat-completion" | |
| MODEL_ID = "GPT-4" | |
| # LLM to use (set to GPT-4 above) | |
| clarifai_llm = Clarifai( | |
| pat=CLARIFAI_PAT, user_id=USER_ID, app_id=APP_ID, model_id=MODEL_ID) | |
| # Type of Langchain chain to use, the "stuff" chain which combines chunks retrieved | |
| # and prepends them all to the prompt | |
| qa = RetrievalQA.from_chain_type( | |
| llm=clarifai_llm, | |
| chain_type="stuff", | |
| retriever=clarifai_vector_db.as_retriever() | |
| ) | |
| return qa | |
| def main(): | |
| user_question = st.text_input("Ask a question to GPT 3.5 Turbo model about your documents and click on get the response") | |
| with st.sidebar: | |
| st.subheader("Add your Clarifai PAT, USER ID, APP ID along with the documents") | |
| # Get the USER_ID, APP_ID, Clarifai API Key | |
| CLARIFAI_PAT = st.text_input("Clarifai PAT", type="password") | |
| USER_ID = st.text_input("Clarifai user id") | |
| APP_ID = st.text_input("Clarifai app id") | |
| uploaded_files = st.file_uploader( | |
| "Upload your PDFs here", accept_multiple_files=True) | |
| if not (CLARIFAI_PAT and USER_ID and APP_ID and uploaded_files): | |
| st.info("Please add your Clarifai PAT, USER_ID, APP_ID and upload files to continue.") | |
| elif st.button("Get the response"): | |
| with st.spinner("Processing"): | |
| # process pdfs | |
| docs = load_chunk_pdf(uploaded_files) | |
| # create a vector store | |
| clarifai_vector_db = vectorstore(USER_ID, APP_ID, docs, CLARIFAI_PAT) | |
| # 2. Vector Creation: create Q&A chain | |
| conversation = QandA(CLARIFAI_PAT, clarifai_vector_db) | |
| # 3. Querying: Ask the question to the GPT 4 model based on the documents | |
| # This step also combines 4. retrieval and 5. Prepending the context | |
| response = conversation.run(user_question) | |
| st.write(response) | |
| if __name__ == '__main__': | |
| main() |
view raw5-all.py hosted with ❤ by GitHub
大型语言模型的检索增强生成(RAG)介绍
我们为这个教程创建了一个模块。您可以按照这些指示使用Clarifai模板创建自己的模块,或者直接在Clarifai Portal上使用这个模块本身。
大型语言模型(LLM)如GPT-3和GPT-4的出现彻底改变了人工智能领域。这些模型擅长生成类似人类的文本,回答问题,甚至创作具有说服力和连贯性的内容。然而,LLM也存在一些缺点;它们经常依赖于其训练数据中嵌入的过时或不正确的信息,并且可能产生不一致的回答。在潜力和可靠性之间存在的差距就是RAG发挥作用的地方。
RAG是一个创新的AI框架,旨在通过将其与准确和最新的外部知识库联系起来,增强LLMs的能力。RAG通过检索相关事实和数据来丰富LLMs的生成过程,以提供既令人信服又基于最新信息的回答。RAG既可以提高回答的质量,又可以提供生成过程的透明度,从而在基于AI的应用中培养信任和可信度。
RAG在一个多步骤的过程中运作,对传统的LLM输出进行了改进。它从数据组织开始,将大量的文本转化为更小、更易消化的块。这些块被表示为向量,它们作为特定信息的唯一数字地址。在收到查询后,RAG探索其庞大的向量数据库,以识别最相关的信息块,然后将其作为上下文提供给LLM。这个过程类似于在提问之前提供参考资料,但是在幕后进行处理。
RAG为LLM提供了一个丰富的提示,该提示现在配备了当前和相关的事实,以生成回答。这个回复不仅仅是模型内部的统计词语关联的结果,而是一段更加扎实和知情的文本,与输入的查询相一致。检索和生成过程是隐形的,为最终用户提供了一个准确、可验证和完整的答案。
这个简短的教程旨在通过使用streamlit、langchain和Clarifai库的实现示例,展示开发人员如何构建利用LLMs的优势并通过RAG减轻其限制的系统。
再次,您可以按照这些指示使用Clarifai模板创建自己的模块,或者只需在Clarifai门户上使用此模块本身,即可在不到5分钟内开始使用!
数据组织
在使用RAG之前,您需要将数据组织成可管理的部分,以便AI稍后可以参考。以下代码段用于将PDF文档分解为较小的文本块,然后由嵌入模型使用这些文本块创建向量表示。
代码解释:
该函数将上传的PDF文件读入内存。然后使用一个 CharacterTextSplitter 将这些文档的文本分割成1000个字符的块,没有任何重叠。
| # 1. Data Organization: chunk documents | |
| @st.cache_resource(ttl="1h") | |
| def load_chunk_pdf(uploaded_files): | |
| # Read documents | |
| documents = [] | |
| temp_dir = tempfile.TemporaryDirectory() | |
| for file in uploaded_files: | |
| temp_filepath = os.path.join(temp_dir.name, file.name) | |
| with open(temp_filepath, "wb") as f: | |
| f.write(file.getvalue()) | |
| loader = PyPDFLoader(temp_filepath) | |
| documents.extend(loader.load()) | |
| text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0) | |
| chunked_documents = text_splitter.split_documents(documents) | |
| return chunked_documents |
view raw1-data.py hosted with ❤ by GitHub
矢量创建
一旦您将文档分块,您需要将这些块转换为向量——这是AI能够高效理解和操作的形式。
代码解释:
该函数 vectorstore 负责使用Clarifai创建一个向量数据库。它接收用户凭证和分块的文档,然后使用Clarifai的服务存储文档向量。
| # Create vector store on Clarifai for use in step 2 | |
| def vectorstore(USER_ID, APP_ID, docs, CLARIFAI_PAT): | |
| clarifai_vector_db = Clarifai.from_documents( | |
| user_id=USER_ID, | |
| app_id=APP_ID, | |
| documents=docs, | |
| pat=CLARIFAI_PAT, | |
| number_of_docs=3, | |
| ) | |
| return clarifai_vector_db |
view raw2-vector.py hosted with ❤ by GitHub
设置问答模型
将数据整理成向量后,您需要设置使用准备好的文档向量的Q&A模型,该模型将使用RAG。
代码解释:
QandA 函数使用Langchain和Clarifai设置一个 RetrievalQA 对象。这是在这里,Clarifai的LLM模型被实例化,并且RAG系统使用"stuff"链类型进行初始化。
| def QandA(CLARIFAI_PAT, clarifai_vector_db): | |
| from langchain.llms import Clarifai | |
| USER_ID = "openai" | |
| APP_ID = "chat-completion" | |
| MODEL_ID = "GPT-4" | |
| clarifai_llm = Clarifai( | |
| pat=CLARIFAI_PAT, user_id=USER_ID, app_id=APP_ID, model_id=MODEL_ID) | |
| qa = RetrievalQA.from_chain_type( | |
| llm=clarifai_llm, | |
| chain_type="stuff", | |
| retriever=clarifai_vector_db.as_retriever() | |
| ) | |
| return qa |
view raw3-qa.py hosted with ❤ by GitHub
用户界面和交互
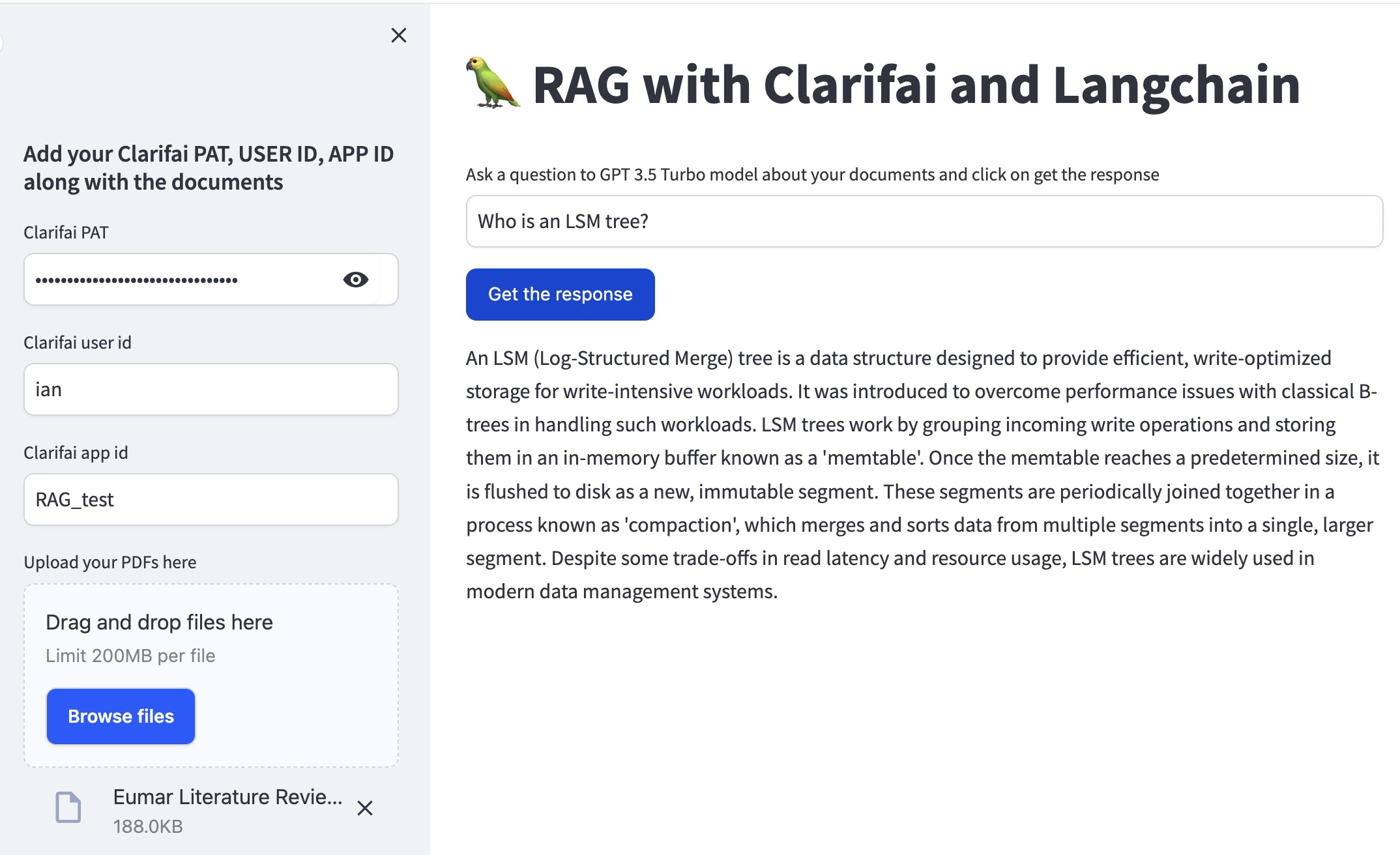
在这里,我们创建了一个用户界面,用户可以在其中输入他们的问题。收集输入和凭据,并在用户请求时生成响应。
代码解释:
这是使用Streamlit创建用户界面的 main 函数。用户可以输入他们的Clarifai凭证,上传文档并提问。该函数负责读取文档,创建向量存储,并运行问答模型以生成用户问题的答案。
| def main(): | |
| user_question = st.text_input("Ask a question to GPT 3.5 Turbo model about your documents and click on get the response") | |
| with st.sidebar: | |
| st.subheader("Add your Clarifai PAT, USER ID, APP ID along with the documents") | |
| CLARIFAI_PAT = st.text_input("Clarifai PAT", type="password") | |
| USER_ID = st.text_input("Clarifai user id") | |
| APP_ID = st.text_input("Clarifai app id") | |
| uploaded_files = st.file_uploader( | |
| "Upload your PDFs here", accept_multiple_files=True) | |
| if not (CLARIFAI_PAT and USER_ID and APP_ID and uploaded_files): | |
| st.info("Please add your Clarifai PAT, USER_ID, APP_ID and upload files to continue.") | |
| elif st.button("Get the response"): | |
| with st.spinner("Processing"): | |
| docs = load_chunk_pdf(uploaded_files) | |
| clarifai_vector_db = vectorstore(USER_ID, APP_ID, docs, CLARIFAI_PAT) | |
| conversation = QandA(CLARIFAI_PAT, clarifai_vector_db) | |
| response = conversation.run(user_question) | |
| st.write(response) | |
| if __name__ == '__main__': | |
| main() |
view raw4-main.py hosted with ❤ by GitHub
这里的最后一段代码是应用程序的入口点,如果直接运行脚本,Streamlit用户界面将被执行。它从用户输入到显示生成的答案,协调整个RAG过程。
将所有东西放在一起
这是该模块的完整代码。您可以在这里查看它的GitHub存储库,并在Clarifai平台上将其作为模块使用。
| import streamlit as st | |
| import tempfile | |
| import os | |
| from langchain.document_loaders import PyPDFLoader | |
| from langchain.text_splitter import CharacterTextSplitter | |
| from langchain.vectorstores import Clarifai | |
| from langchain.chains import RetrievalQA | |
| from clarifai.modules.css import ClarifaiStreamlitCSS | |
| st.set_page_config(page_title="Chat with Documents", page_icon="🦜") | |
| st.title("🦜 RAG with Clarifai and Langchain") | |
| ClarifaiStreamlitCSS.insert_default_css(st) | |
| # 1. Data Organization: chunk documents | |
| @st.cache_resource(ttl="1h") | |
| def load_chunk_pdf(uploaded_files): | |
| # Read documents | |
| documents = [] | |
| temp_dir = tempfile.TemporaryDirectory() | |
| for file in uploaded_files: | |
| temp_filepath = os.path.join(temp_dir.name, file.name) | |
| with open(temp_filepath, "wb") as f: | |
| f.write(file.getvalue()) | |
| loader = PyPDFLoader(temp_filepath) | |
| documents.extend(loader.load()) | |
| text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0) | |
| chunked_documents = text_splitter.split_documents(documents) | |
| return chunked_documents | |
| # Create vector store on Clarifai for use in step 2 | |
| def vectorstore(USER_ID, APP_ID, docs, CLARIFAI_PAT): | |
| clarifai_vector_db = Clarifai.from_documents( | |
| user_id=USER_ID, | |
| app_id=APP_ID, | |
| documents=docs, | |
| pat=CLARIFAI_PAT, | |
| number_of_docs=3, | |
| ) | |
| return clarifai_vector_db | |
| def QandA(CLARIFAI_PAT, clarifai_vector_db): | |
| from langchain.llms import Clarifai | |
| USER_ID = "openai" | |
| APP_ID = "chat-completion" | |
| MODEL_ID = "GPT-4" | |
| # LLM to use (set to GPT-4 above) | |
| clarifai_llm = Clarifai( | |
| pat=CLARIFAI_PAT, user_id=USER_ID, app_id=APP_ID, model_id=MODEL_ID) | |
| # Type of Langchain chain to use, the "stuff" chain which combines chunks retrieved | |
| # and prepends them all to the prompt | |
| qa = RetrievalQA.from_chain_type( | |
| llm=clarifai_llm, | |
| chain_type="stuff", | |
| retriever=clarifai_vector_db.as_retriever() | |
| ) | |
| return qa | |
| def main(): | |
| user_question = st.text_input("Ask a question to GPT 3.5 Turbo model about your documents and click on get the response") | |
| with st.sidebar: | |
| st.subheader("Add your Clarifai PAT, USER ID, APP ID along with the documents") | |
| # Get the USER_ID, APP_ID, Clarifai API Key | |
| CLARIFAI_PAT = st.text_input("Clarifai PAT", type="password") | |
| USER_ID = st.text_input("Clarifai user id") | |
| APP_ID = st.text_input("Clarifai app id") | |
| uploaded_files = st.file_uploader( | |
| "Upload your PDFs here", accept_multiple_files=True) | |
| if not (CLARIFAI_PAT and USER_ID and APP_ID and uploaded_files): | |
| st.info("Please add your Clarifai PAT, USER_ID, APP_ID and upload files to continue.") | |
| elif st.button("Get the response"): | |
| with st.spinner("Processing"): | |
| # process pdfs | |
| docs = load_chunk_pdf(uploaded_files) | |
| # create a vector store | |
| clarifai_vector_db = vectorstore(USER_ID, APP_ID, docs, CLARIFAI_PAT) | |
| # 2. Vector Creation: create Q&A chain | |
| conversation = QandA(CLARIFAI_PAT, clarifai_vector_db) | |
| # 3. Querying: Ask the question to the GPT 4 model based on the documents | |
| # This step also combines 4. retrieval and 5. Prepending the context | |
| response = conversation.run(user_question) | |
| st.write(response) | |
| if __name__ == '__main__': | |
| main() |
view raw5-all.py hosted with ❤ by GitHub